Wine and music:
- please our senses,
- touch our emotions,
- beg to be shared,
- are deeply engrained in how we define ourselves and,
- can determine how other people judge us.
Because of those factors, every recommendation system in use today — including those deployed by Pandora, Spotify, Slacker and other online music sites — fail because of:
- genetic,
- psychological,
- cultural, and educational factors.
While the links (above) discuss those failure factors, in the context of wine, the principles and most of the specifics apply equally to books, movies and other products and services “of taste.”
Collaborative Filtering At The Core Of Failure
The image, below is from “Collaborative Filtering at Spotify,” slide 4 of a SlideShare presentation by Pandora’s über-talented Engineering Manager, Erik Bernhardsson.
The 63-slide presentation is an awesome explanation of a process called “collaborative filtering,” which was born in the early days of the web, circa 1994. Most consumers are familiar with collaborative filtering in the “people who bought (liked, faved, rated same) this also bought (liked, faved, rated same) this”
Berhhardsson’s entire presentation is a tour de force, but — like every flavor of collaborative filtering today — gets tripped up by the “probably similar” assumption in slide 4.
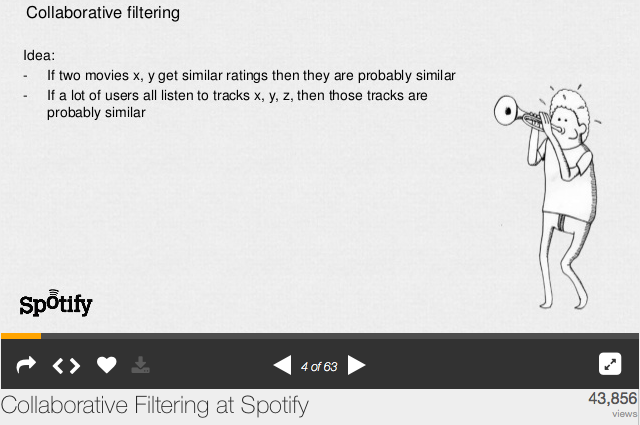
Right-click image to enlarge.
Collaborative Failings
Collaborative filtering is an “inference” system. And “to infer” anything means to make the best possible educated guess possible.
I learned this first hand in the mid-1990s when I designed and prototyped a wine recommendation system based on the first real implementation of collaborative filtering: FireFly which had music recommendation as its first application.
While algorithms have advanced greatly in the past 20 years, collaborative filtering is still a best possible guess clouded by human biases that make it frequently inaccurately and frustrating for consumers. The advent of “big data” has helped collaborative filtering inch its way toward a tolerable level of accuracy, but its returns are rapidly diminishing (see: How Predictive Big Data Fails).
Why Slide #4 Is The Root Of Failure
Experience and personal bias plague every rating system no matter whether it consists of points, stars or other variables. Ratings also carry the psychological connotation that they represent some sort of objective assessment of overall quality. See Rating The Rating Systems for more.
More importantly, especially when dealing with music, is the irrelevance of the “fave” system.
This is because faves and likes are one step above a troll: neither carries a “cost.” They require little effort, are easily reversible and subject to the whims of the moment. They are also subject to peer pressure when they are shared publicly.
“Probably Similar” Another Failure Epicenter
Humans who create the algorithms are …. well … human (most of us are). That means that the best examination and definition of “similar” may not be exactly correct. And slide #4 states the problem: “probably” is another word for “maybe.”
And “similar” is another way of saying, “maybe the same.”
There are no hard and fast rules, but each algorithmic mistake usually makes the next step less accurate. They are rarely additive and almost never subtractive. No, nothing so lucky as that.
So, (maybe + maybe ) rarely = 2 mabyes. And we never get (maybe – maybe) = 0 or maybe/2.
Because the algorithm gods hate mortals who tread on their divine territory, the result is usually multiplicative: (maybe x maybe ) or to a higher power: maybe2.
This is to say that every sequential “similar” makes every following step less accurate.
No matter how good your algorithm is, early uncertainties undermine everything downstream.
Content Filtering Systems: Profiling
Content filtering systems aim to improve on collaborative filtering by extracting the relevant characteristics of a product and creating a profile of those characteristics.
Next, the system must create a way to create a profile for every user. Finally, the system must match people with product profiles.
Bias and failure are built in because those creating the system must judge which product characteristics are most relevant to a given consumer.
In reality, even if algorithm creators were perfect and managed to nail every relevant characteristic, not all characteristics are equal. In addition, the importance of characteristics may change with mood and context.
I tried to move beyond collaborative filtering in 1996 with the creation of my first profile-based wine recommendation system, SmartTaste.
A substantially improved version of that, SavvyTaste became a popular Facebook app.
SavvyTaste and SmartTaste failed because profile-based systems exhibit the same sorts of shortcomings as collaborative filtering. See: Profile Matching for more data on those failures.
Dirty Big Data
Most web sites dealing wine, music, books present the user with an average rating for a product before they rate. (This is a massive bias. For a more extensive look at this, please see Anxiety, Stress and Social Pressure Sabotage Choice.)
Privacy Concerns
Tmmense legal and regulatory privacy issues are inherent in other recommendation systems. The “big data collection” used by most significant recommendation engines has exploded into major user privacy concerns. Those concerns make merchants easy targets for legal and regulatory bodies, especially in Europe.
Shared Experience Amps Up Social Pressure
In addition, public ratings are subject to intense peer pressure especially with wine and music. When those are shared in social media, ratings will be biased toward friends. This means that ratings — and even action-oriented preference expressions can be skewed.
Anonymous, Action-Oriented = Most Accurate
This is requires an anonymous, self-learning social meta-data clustering system that can work as a parallel system to existing recommendation systems.
This means that a user whose friends trend toward alternative/indie can publicly share songs in that genre that they genuinely like while safely and secretly getting recommendations connected to their love of Florida/Georgia Line or Neil Young or Abba.
A wine lover who truly loves a Chateau Margaux AND Cupcake Cabernet can get accurate recommendations on both.
What’s more, companies can make opt-in coupons or other offers that satisfy a variety of tastes that could not accurately be satisfied using public social expressions.
The key, then, is how best to organize the data in this anonymous social network that brings together expression metadata rather than simply people or products
Experience Is In The Genes
In the context of wine, this article: Inherited Taste Chaos Sabotages Recommendations shows how genes determine how differently people can experience the same wine. Music follows the same genetic determinations.
“It’s always interesting to me that we all hear music differently. It’s an awesome experience to hear what other people hear.” — Motley Crüe’s Tommy Lee
Music happens inside the head.
Before that, it’s just a boatload of acoustic vibrations. If Bon Iver sings in the forest and there is no one to hear him, does his voice make a song?
More seriously, the experience of music depends on a genetic crapshoot: As a fetus grows into an infant grows into an adult:
- How will the cochlea of the inner ear develop?
- How will the bones near the ear develop?
- How will the nerves leading to the initial nerve processing centers in the brain develop?
- How will the final auditory centers of the brain develop?
- How will that processed acoustic data be passed on to the brain’s emotional centers?
- Finally, how will the centers of consciousness combine the emotion and the acoustic data so that an experience happens?
All of those factors involve individual genetic development that affect the way different people, have different experiences with the same music (or wine).
Just as there are tone deaf people and those with perfect pitch, a million different factors combine to make experiencing music a unique experience.
Trying to profile that individuality is an possible task.
A recent analytical-based system for profiling wines shows that hopes for profiling still live, but carry a lot of other bias baggage. (Next Glass: A Step In Solving Wine Rating’s Genetic Issues)
Dogs, People & Recommendation Engines
Big data, collaborative filtering, and profile-based content filtering systems treat people like dogs and other pets.
Few of us who are owned by our dogs and pets fail to wonder what they are thinking. We can’t speak dog and dogs don’t speak people.
If we pay close attention, we begin to make inferences that are valid most of the time (hungry, need to go potty). Trying to read a canine thought balloon past those basics often involves projecting human emotions and trying to act on those.
Some very smart people like behavioral scientist Alexandra Horowitz apply everything they have learned about dogs and end up writing a book like Inside of a Dog: What Dogs See, Smell, and Know.
Horowitz’s book is enlightning, entertaining and — in the end — yields about the same amount of inferential data about dogs as today’s recommendation engines do about what people really want to buy.
Significantly, people have it all over dogs because we can ask someone a question and they will tell us things.
But, as bias, peer pressure, pre-expression product ratings and other factors show us, how we ask a question can determine what answers we get. And many factors will prevent people from being honest in their responses.
And, even once those factors are neutralized, accuracy depends upon how the answers are used.
A Personal Note And Self-Selected Playlist
Over the past four years I have used Pandora, Spotify,Rdio, and Slacker Radio.
None of these services have done an accurate job of recommending music for me.
I have had premium subscriptions at Pandora and Spotify but dropped those because of recommendation failures
I have stuck with a premium subscription to Slacker, not because it gives me good recommendations, but because it has the largest music library to browse and look for good music..
This is a link to my playlist of favorites: Music Recommendation Engines: Epic Fail For Me